

Solving the Challenges for Big Data Training

Can you cope with new data?

In many industries, data is constantly generated, quickly rendering AI models outdated. The challenge lies in continuously integrating new data and learnings into existing models. But is this feasible?
STADLE addresses this challenge by enabling the seamless addition of new data to existing models. This ensures that AI systems remain up-to-date and effective, leveraging both centralized and decentralized learning to optimize and orchestrate intelligence globally.
Enterprises AI comes with multiple challenges ...
Bias
Model bias due to lack of a wider data from human bias or data collection

Overfitting
ML models learning from noise and inaccuracies as the data set is too large

Underfitting
Making wrong predictions due to high bias and low variance with small dataset

Inconsistency
Training on irrelevant low quality data leading to model issues

Data Silos
Data collection issues from all sources due to privacy and other restrictions

Data Sparsity
Insufficient values in a data set impacting ML model performance

Data Security
Unable to access
crucial data due to the risk in data security

Data Storage
Skyrocketing costs
on data transfer and
storage for ML

Privacy by Design
STADLE helps enterprise manage cost, performance, and complexity.
STADLE uses ML techniques that only gathers intelligence and its meta data, not the actual personal data.
Personal data remains safe and secure and never will be taken out of the person’s device or to a cloud.


Train with non-representative data
To create a generalized model with a greater accuracy all types of data that cover different use cases are required to train the model.
Most times this is very challenging due to the nature of data siloed across systems and across organizations
Unlock the true potential of your machine learning model by increasing access to data that was not otherwise available in your data engineering process.
Training with no data transfer gives you tremendous opportunity to increase the performance of your AI model by using external data from partners, vendors and customers.



Significant reduction in data transfer costs
One of the big bottlenecks for training your AI is the data transfer costs over the cloud. Data transfer costs consume around about 30% of the entire project. Training your AI model with lesser data may lead to limited performance of the model.
At the surface level, more data is always a good thing. But the training using huge computation resources takes a lot of time and costs.
STADLE orchestrates intelligence only and helps you to find the right balance between overfitting and underfitting by segregation of training with data vs training with intelligence.
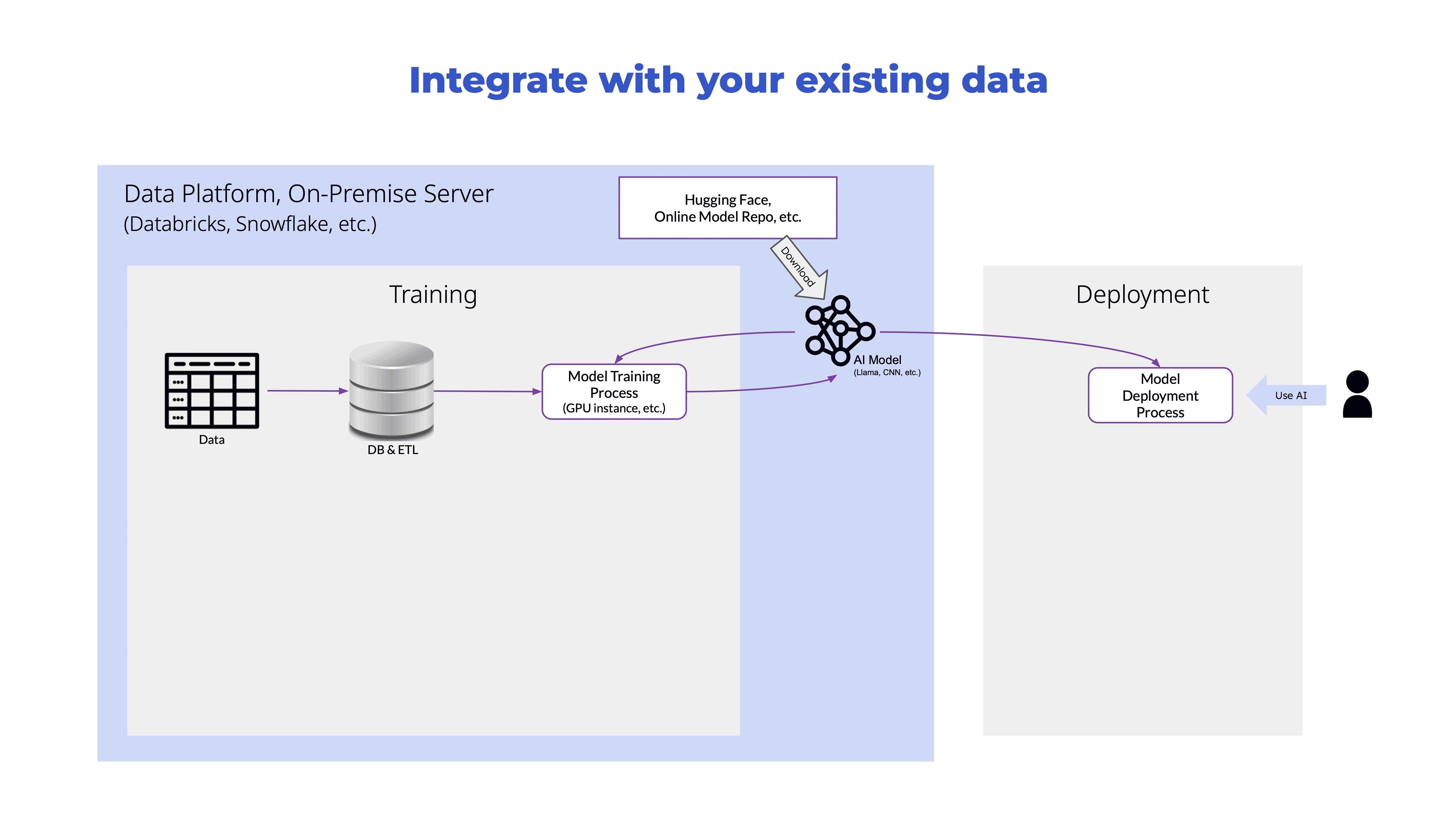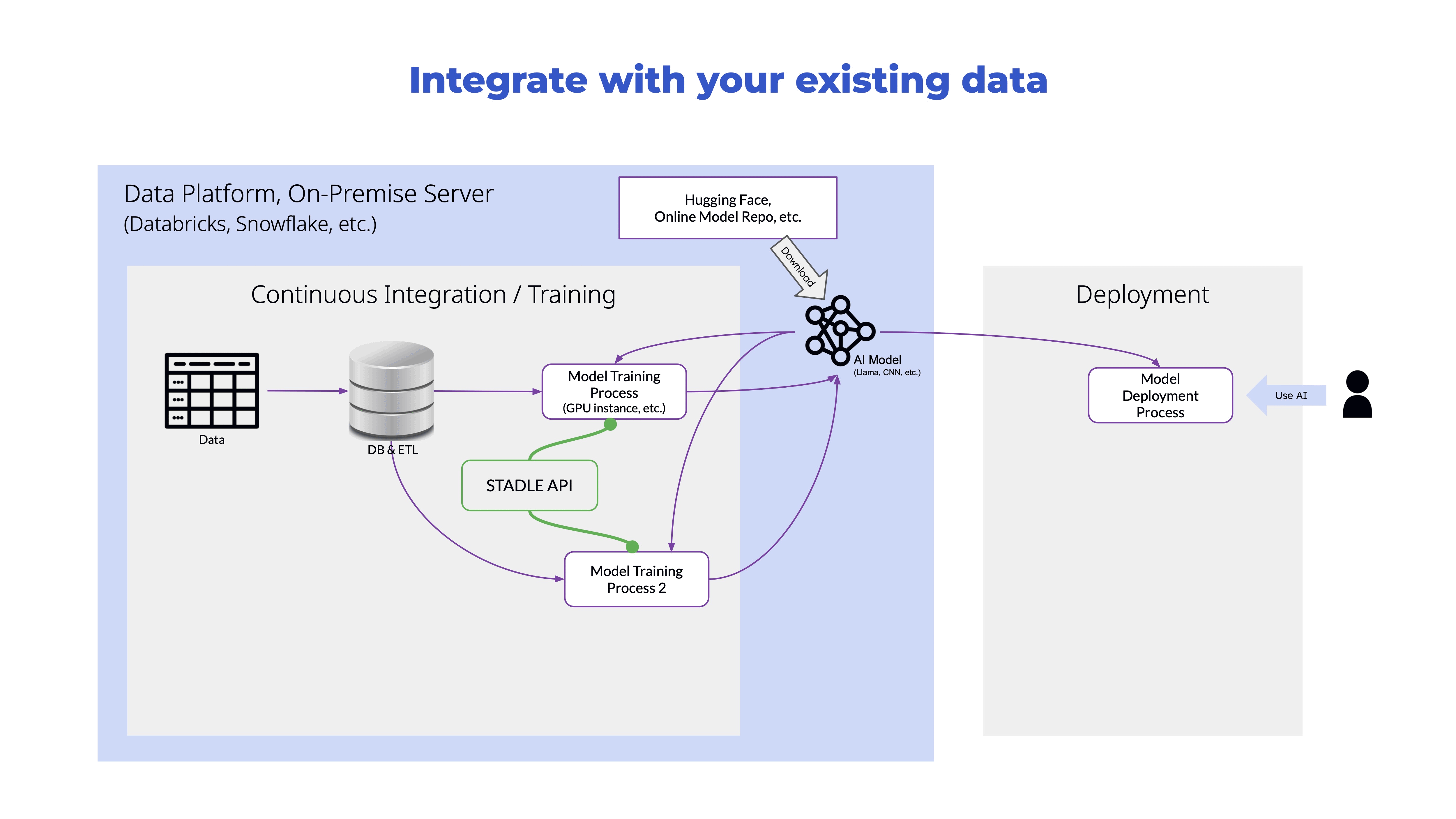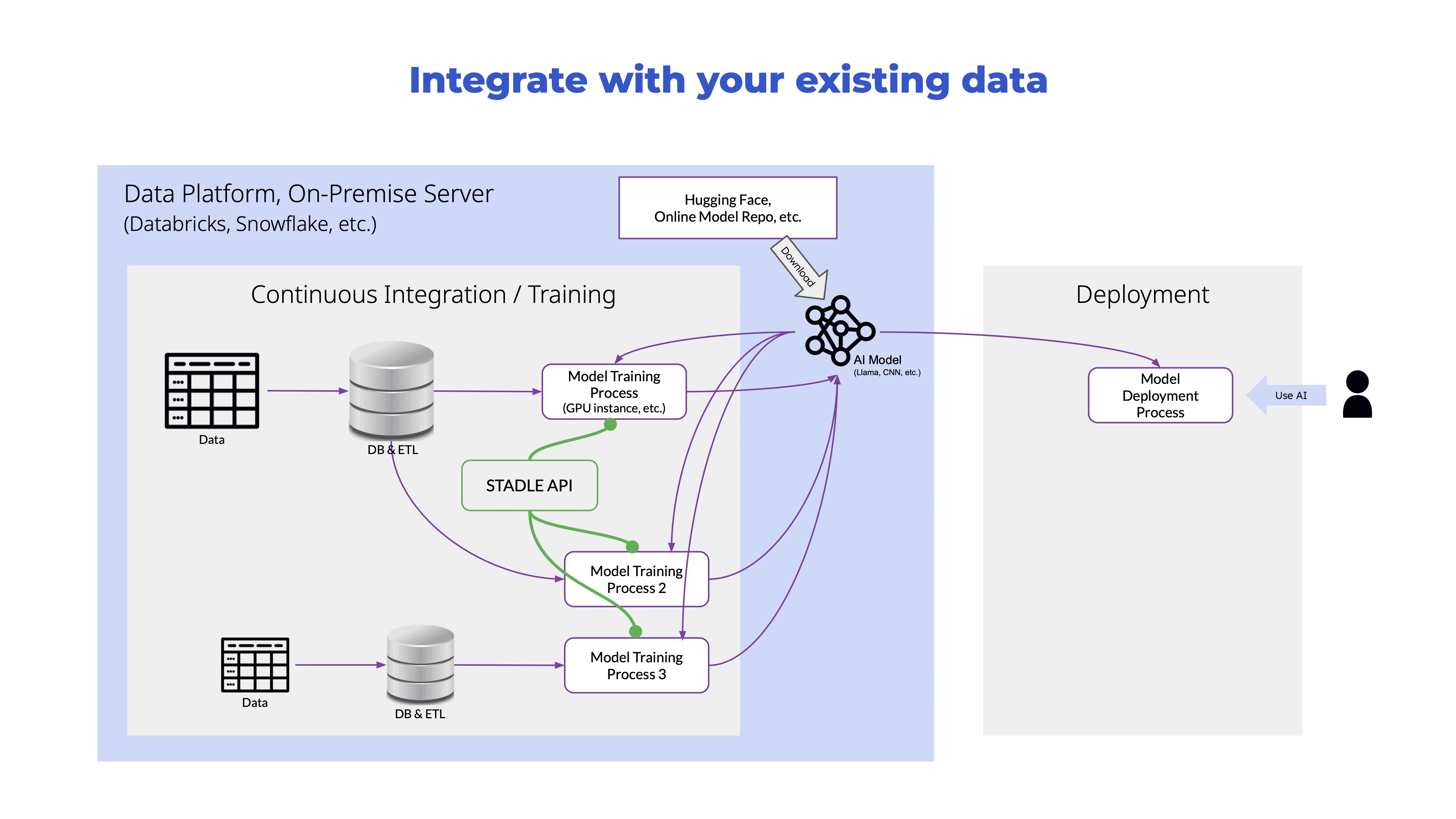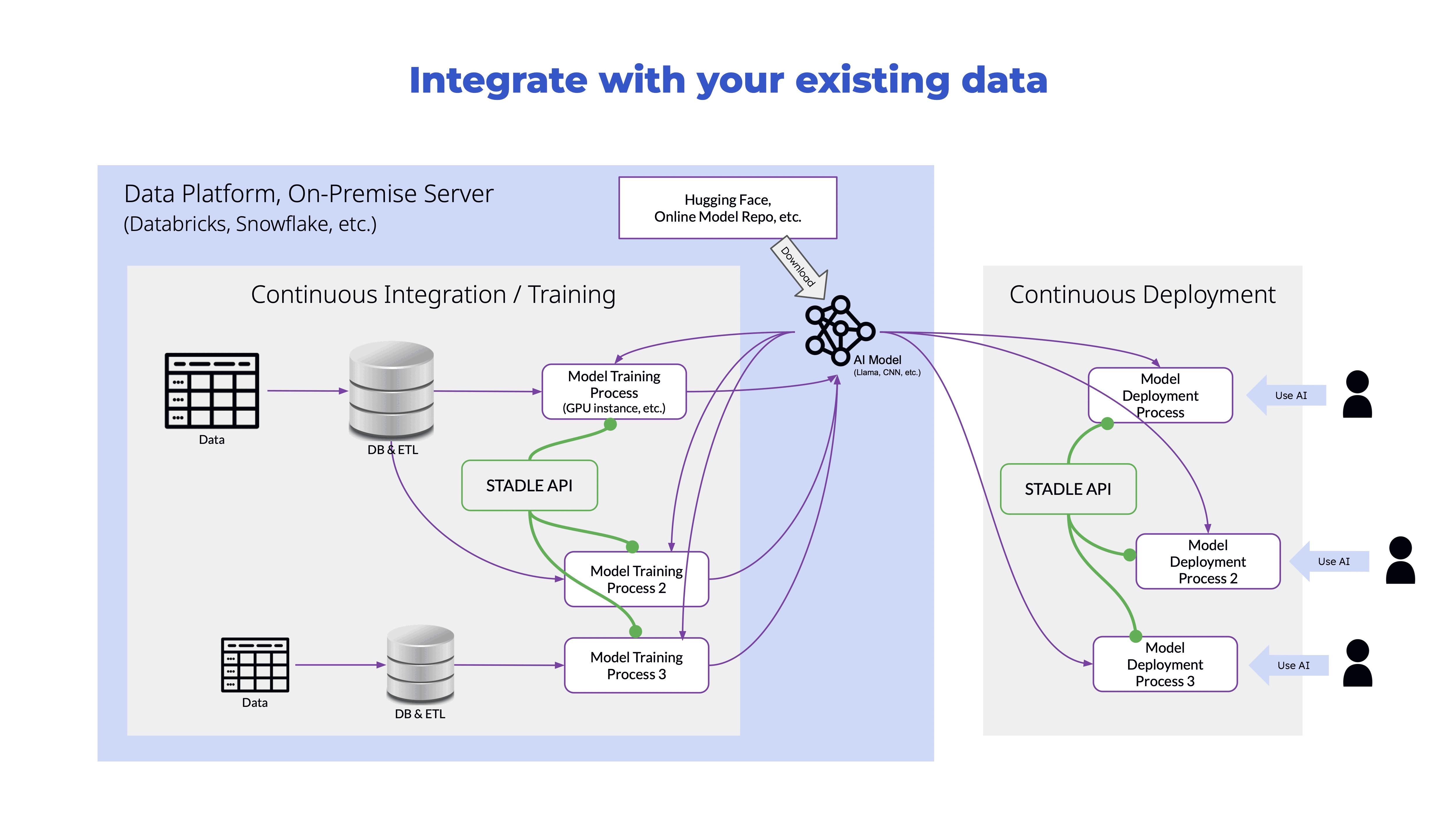

Training at the edge reducing data latency
STADLE accelerates your smart products adoption by training your AI at the edge reducing the data latency and increasing training efficiency.
Your time-sensitive functions in video streaming or autonomous driver systems can respond with a greater precision at a faster pace.
Your sensors need not send huge streams of video data to your cloud but just detect anomalies that accelerates the real-time decision making more efficient. Medical imaging devices don't have to transfer sensitive health images rather send only the intelligence required for evaluation.